
RNN 한계와 해결법
RNN의 문제점
- 긴 문장에 취약함
- 연산의 비효율성
- Transformer 병렬 연산이 가능해질수록(GPU 성능 올라갈수록) 효율이 많이 높아짐
- 하지만 RNN은 리소스를 많이 투입해도 별다른 개선이 없음
- 데이터를 많이 학습해도 효과가 적음
- 그래서 Attention 이라는 기법을 사용함 → 연산이 많을수록 좋음
해결 방안
- RNN으로 Machine Translation과 같은 여러 task를 수행하기엔 성능 부족
- RNN 자체 모델의 한계 때문에 긴 텍스트에서 성능이 떨어지고 많은 텍스트 학습 어려움
- 이를 보완하기 위해 RNN 2개를 연결해 Encoder-Decoder 구조 + attention 연산을 추가해 성능을 향상시킨 기법 등장
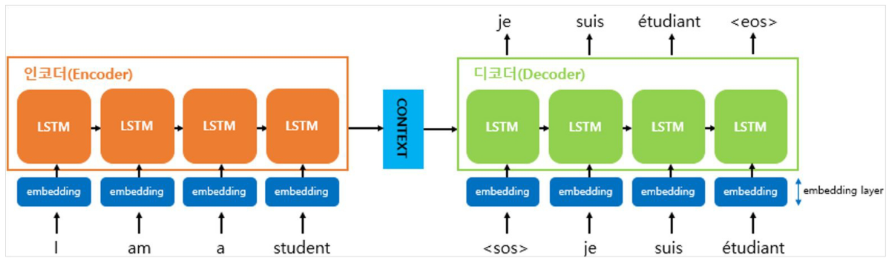
- Encoding : 자연어를 숫자(코드)로 변환(Embedding)
- Decoder
- 코드를 텍스트로 변환(시작에 항상 SOS - Start of sentence를 투입해서 학습의 시작점을 명시)
- 추출 시 eos(End Of Sentence)를 문장 마지막에 넣어서 문장이 끝남을 명시
Auto-Regressive (자동 회귀. encoder-decoder를 알아서 반복)
- 출력을 입력으로 넣는 걸 반복함
- 처음에는 context와 SOS를 투입, 이후에는 je와 sos 투입….. 디코더 출력으로 eos가 나올 때까지 반복
- 문장의 순서가 매우 중요함
- context의 길이가 길어질수록 비효율적인 문제가 생김(정보의 소실 등)
- 각각의 순서를 인/디코딩 애들이 따라가야 함

Attention

주요 특징
동적 가중치 부여
- 출력 시점마다 중요한 부분에 가중치를 동적으로 조절하여 집중
- 입력 시퀀스마다 다른 중요도를 부여한다는 것
Query, Key, Value 구조
- Query: 현재 디코더 상태(출력 단어 관련 정보)
- Key: 인코더 출력을 나타내는 각 입력 요소 벡터
- Value: 입력 정보가 담긴 벡터
- 위의 세 가지를 비교해 유사도를 계산, 어느 입력에 주의를 둘 지 결정함
문맥 정보 유지 및 강화
- 문장의 특정 단어, 구문 등 중요한 부분을 반영
- 긴 시퀀스에서도 문맥 손실을 줄이고 중요한 정보를 정확히 반영
병렬 처리 및 효율성 증가
- RNN의 순차 처리 한계를 극복하여 입력 전체 참조 + 연산, 병렬 처리로 연산 효율이 뛰어남
확률 분호 형태의 가중치
- Attention 점수에 Softmax 함수를 적용하여 0 ~ 1 사이 가중치로 정규화
- 가중치들의 합이 1이 되어 확률 분포처럼 작용
인간의 주의 집중 과정 모방
- 사람의 인지 과정에서 특정 정보에 선택적으로 주의를 기울이는 방식을 수학적으로 모델링

- RNN dependency → Sequential(Self attention) 로 넘어감
- Self-attention은 en/decoder의 맥락 연산, 내가 내 문장 내의 중요한 문장을 판단하겠다
- 원래 디코더는 auto-regression 해야함. Masked 형식은 AR 하는 동안 본인의 앞에 나오는 단어들만 보게끔 제한된 맥락 연산
- en-de attention : decoder가 encoder를 살펴봄
- 맥락 학습 + multi-lingual
- 이제는 아예 encoder 자체를 빼버려도 충분한 양의 텍스트를 학습시키면 성능 개선이 가능할수도 있다
트랜스포머가 가져온 변화
- Attention을 활용한 구조로 더 많은 데이터와 파라미터를 사용 가능
- RNNLM은 병렬 연산을 사용할 파트가 적었지만, Transformer는 병렬 연산이 가능한 구조이기에 GPU를 충분히 활용할 수 있게 됨 → Scalability(확장성) 증가
- RNNLM보다 더 긴 문장/문서에 대해 충분히 맥락 학습 가능
- 이것들 모두 더해져 BERT, GPT, Music Transformer, Vision Transformer가 등장
- 이 중 Transformer Decoder 구조가 모든 LLM의 근간이 됨
반응형