
Naive RAG vs GraphRAG vs OpenKB 전격 비교
최근 엔터프라이즈 환경이나 복잡한 도메인 지식을 다루는 프로젝트에서 LLM을 도입할 때, 단순한 RAG만으로는 한계를 느끼는 분들이 많아지고 있습니다. "A문서와 B문서의 내용을 종합해서 인사이트를 도출해 줘" 같은 질문에 AI가 이상한 문서를 찾아와서 그걸 기반으로 대답을 내놓는 것을 보며 답답하셨던 경험, 다들 한 번쯤 있으실 겁니다.
AI 씬에서는 이 '파편화된 지식의 연결'이라는 난제를 풀기 위해 다양한 아키텍처가 쏟아져 나오고 있습니다. 오늘은 그중에서도 가장 대표적인 세 가지 패러다임인 1) Naive RAG, 2) 지식 그래프 기반의 GraphRAG, 그리고 최근 주목받는 3) 위키 컴파일 방식의 OpenKB를 아키텍처부터 실제 구현 예시까지 비교해 보겠습니다.
1. Naive RAG (단순 검색 기반 RAG)
가장 널리 쓰이고, 우리가 처음 RAG를 배울 때 구축하는 표준적인 형태입니다.
작동 방식
문서를 일정 크기의 텍스트 조각(Chunk)으로 자른 뒤, 임베딩 모델을 통해 벡터(Vector) 숫자로 변환하여 벡터 DB에 저장합니다. 사용자가 질문하면 유사도가 가장 높은 조각들을 찾아와 LLM에게 "이것들을 참고해서 대답해"라고 던져줍니다.
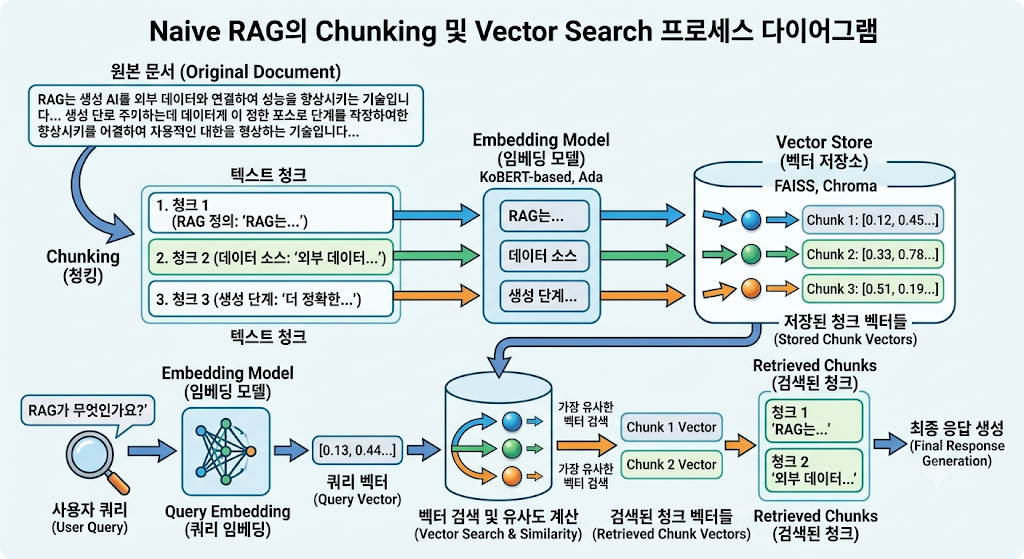
실제 구성 예시 (LangChain & ChromaDB)
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# 1. 문서 로드 및 청킹 (보통 1000토큰 단위)
loader = PyPDFLoader("architecture_v1.pdf")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
splits = text_splitter.split_documents(docs)
# 2. 벡터 DB 적재
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# 3. 쿼리 검색
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
docs = retriever.invoke("데이터베이스 이중화는 어떻게 처리했어?")
장단점
- 장점: 구축이 매우 빠르고 직관적입니다. 단순한 사실 확인이나 단일 문서 기반 QA에서는 최고의 효율을 냅니다.
- 단점: '글로벌 맥락(Global Context)'의 상실. 10페이지에 있는 원인과 50페이지에 있는 결과가 각각 다른 청크로 쪼개져 있다면, 둘 다 한 번에 검색되지 않는 이상 LLM은 둘의 관계를 절대 알 수 없습니다. 운에 맡겨야 하므로 맥락의 파악이 어렵습니다.
2. GraphRAG (지식 그래프 기반 RAG)
Naive RAG의 '연결성 부족'을 해결하기 위해 등장한 구조입니다.
마이크로소프트의 GraphRAG나 HKU의 LightRAG가 대표적입니다.
작동 방식
문서를 청킹하는 것은 같지만, LLM을 시켜 각 청크 안에서 개체(Entity)와 그들 간의 관계(Relationship)를 수학적인 그래프(Node와 Edge)로 추출합니다. 이를 Neo4j 같은 그래프 DB에 저장하여, 지식 간의 다중 홉(Multi-hop) 추론을 가능하게 합니다.
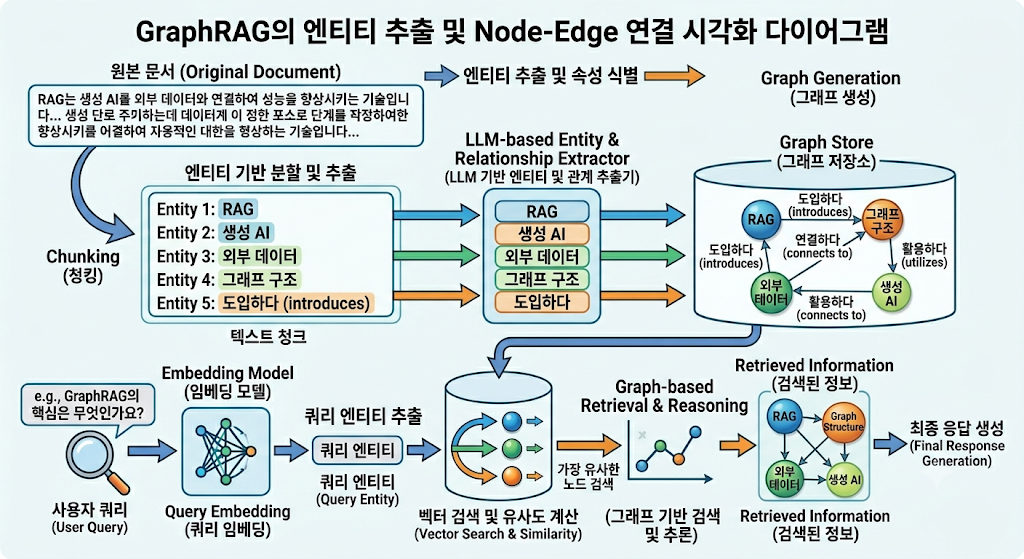
실제 구성 예시 (Neo4j Cypher 쿼리 및 개념)
데이터는 텍스트가 아니라 아래와 같은 '트리플(Triple)' 구조로 저장됩니다.[마이크로서비스] --(대체한다)--> [모놀리식 구조]
데이터베이스 내부에서는 다음과 같은 쿼리로 탐색이 일어납니다.
// Neo4j에서 특정 개념과 연관된 2단계 깊이의 지식을 탐색하는 Cypher 쿼리 예시
MATCH (e:Entity {name: '데이터베이스 이중화'})-[r1*1..2]-(connected_entity)
RETURN e, r1, connected_entity
LIMIT 10
장단점
- 장점: 복잡하고 거대한 데이터셋에서 "A와 B 사이에 숨겨진 연관성은 무엇인가?" 같은 고도화된 추론 쿼리에 압도적으로 강합니다. 전체 데이터셋의 요약(Global Query)에도 탁월합니다.
- 단점: 극악의 구축/운영 난이도와 비용. 엔티티를 추출하는 과정에서 LLM 호출 비용이 폭발적으로 증가하며, Neo4j 같은 전용 그래프 DB 인프라를 운영해야 합니다. 추출된 생(Raw) 데이터는 사람이 직접 읽고 맥락을 이해하기 매우 어렵습니다. graphml을 http로 변환하여 시각적 확인은 가능하나 쉽지 않습니다.
- 물론, LightRAG의 경우 단일 컬렉션의 경우 GraphDB를 사용하지 않거나, sql과 연동하여 사용할 수 있다지만 컬렉션이 많아지고 데이터가 방대해진다면 어쩔 수 없이 GraphDB의 도입이 필수적이라고 생각합니다.
3. OpenKB (위키 컴파일 기반 지식 베이스)
Andrej Karpathy의 아이디어를 바탕으로, 기계적인 연결(Graph)이 아닌 사람이 읽을 수 있는 문서(Wiki) 형태로 지식을 합성하는 새로운 접근법입니다. 쉽게 말해 문서들을 사용하여 나무위키를 만들고, 그걸 기반으로 문서들을 검색(Retrieve)하는 방식이라고 생각하시면 됩니다.
작동 방식
문서를 벡터로 쪼개거나 노드로 분해하는 대신, LLM이 문서를 직접 읽고 요약합니다(긴 문서는 PageIndex 트리 활용). 그리고 기존 지식과 결합하여 마크다운(.md) 형태의 개념(Concept) 페이지를 직접 집필하고 갱신합니다.
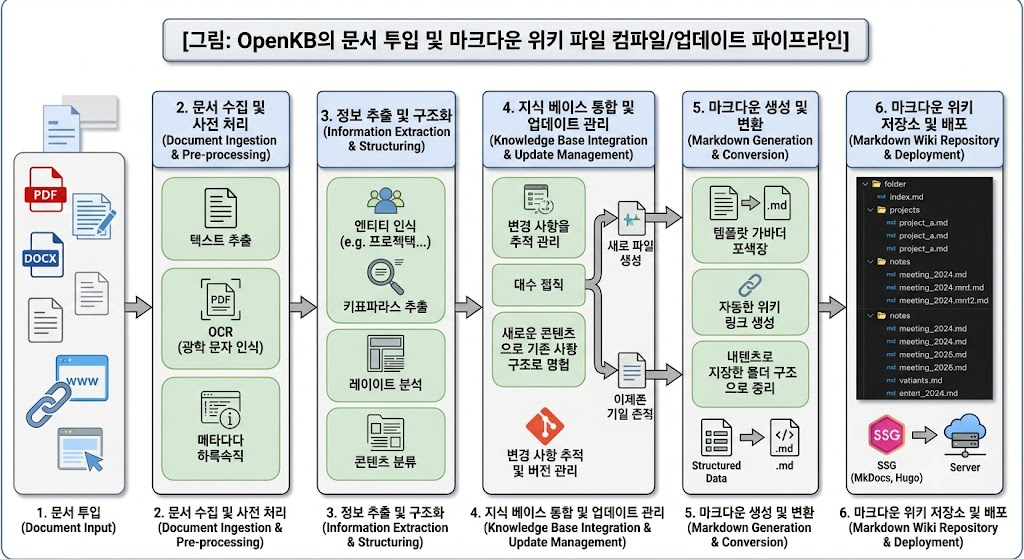
실제 구성 예시 (CLI 및 마크다운 결과물)
복잡한 DB 셋업 없이, 로컬 폴더 자체가 지식 베이스가 됩니다.
# 초기화 및 문서 투입
openkb init
openkb add ./docs/architecture_v1.pdf
openkb add ./docs/architecture_v2.pdf
# 컴파일 완료 후 생성된 실제 파일 구조
wiki/
├── concepts/
│ └── database_replication.md # LLM이 직접 융합하여 작성한 위키 문서
이때 생성된 database_replication.md의 내부는 다음과 같습니다.
# Database Replication
...
* **V1 아키텍처**: 단일 구조를 사용함. ([[architecture_v1_요약.md]] 참조)
* **V2 마이그레이션**: Active-Active 클러스터로 개편. ([[architecture_v2_요약.md]] 참조)
> **Lint 경고**: V1과 V2 문서 사이에 지연 시간에 대한 충돌된 기록이 있습니다.
장단점
- 장점: 사람과 기계의 완벽한 협업. 생성된 지식이 줄글(Narrative) 형태의 마크다운이므로 비개발자도 읽고 이해할 수 있습니다. 환각이나 오류가 발생하면 그저 마크다운 파일을 열어 텍스트를 수정하고 저장하면 끝입니다(초간단 유지보수). 전용 DB 인프라가 필요 없습니다 => 마크다운 파일로 DB를 만들었다고 생각하시면 됩니다.
- 단점: 구조화된 수치 데이터(예: 수백만 건의 금융 트랜잭션 로그)를 수학적으로 연산하거나 탐색하는 데는 부적합합니다. '텍스트 위주의 문서'에 특화되어 있습니다. 즉, 그림이나 표가 들어간 문서가 많은 경우 성능이 하락할 수 있습니다.
4. 한눈에 보는 요약 비교표
| 비교 항목 | Naive RAG | GraphRAG (지식그래프) | OpenKB (위키 컴파일) |
|---|---|---|---|
| 핵심 구조 | 벡터 유사도 기반 텍스트 조각(Chunk) | 노드(Node)와 엣지(Edge)의 수학적 연결 | LLM이 직접 융합한 마크다운(Markdown) 위키 |
| 적합한 데이터 | 단순 매뉴얼, 독립적인 개별 문서 | 복잡하게 얽힌 엔티티(금융, 신약 개발 등) | 논문, 기획서, 서로 맥락이 이어지는 기술 문서 |
| 구축/운영 인프라 | 보통 (Vector DB 필요) | 매우 높음 (Graph DB, 방대한 LLM 비용) | 낮음 (로컬 파일 시스템, 가상환경) |
| 사람의 가독성 | 낮음 (파편화된 청크) | 매우 낮음 (수학적 관계 데이터) | 매우 높음 (줄글 형태의 블로그/위키) |
| 유지보수 방법 | 원본 수정 후 다시 청킹/임베딩 | 그래프 DB 쿼리로 노드 관계 수정 | 마크다운 파일(.md) 직접 타이핑 수정 |
마치며: 어떤 방법을 선택해야 할까요?
정답은 데이터의 성격과 팀의 운영 능력, 개발하고자 하는 AI의 수준에 달려 있습니다.
- 단순히 "취업 규칙 15조 내용 찾아줘" 수준의 챗봇이 필요하다면 Naive RAG로 충분합니다.
- 데이터 간의 복잡한 추론 로직이 필요하고 인프라/비용을 감당할 수 있는 대규모 엔터프라이즈라면 GraphRAG가 강력한 무기가 될 것입니다.
- 여러 문서를 엮어 사내 기술 블로그나 개인 연구 노트를 만들고 싶고, 비전공자도 쉽게 지식을 열람하고 수정할 수 있는 시스템을 원한다면 OpenKB를 추천드립니다.
이 글이 여러분의 다음 AI 프로젝트 아키텍처 선정에 명확한 기준이 되기를 바랍니다.
'AI 관련 지식 > RAG' 카테고리의 다른 글
| [OpenKB] OpenKB란? (1) | 2026.05.15 |
|---|---|
| [지식 그래프] LightRag란? (1) | 2026.04.12 |
| [vector DB] Weaviate 기본 정리 (0) | 2025.09.10 |